

Introduction
There is no doubt that society has become obsessed with physical image. In the advent of the ‘selfie’ we have been bombarded by images of glamour and beauty. Advances in technology and the editing and manipulation of photos driven by social media has reinforced the drive towards perfection. This has led to users becoming more anxious, less confident and feeling less physically attractive afterwards.1–3 Needless to say, patients with any physical deformity are left feeling marginalised compared to their peers in a world where even ‘normal’ appears not to be good enough. Patients with a cleft lip and/or palate continue to be faced with the stigma of their appearance.
Early psychometric findings from the Cleft-Q study show that participants who were unhappy with how they looked reported significantly lower scores on all appearance and health-related quality of life scales. Mean scores for health-related quality of life and speech scales were highest for the group without a speech problem and lowest for the group with a moderate or severe speech problem.4 Appearance and speech therefore appear to be the two important factors influencing quality of life.
Assessment of aesthetic outcomes is a difficult problem. Nevertheless, it should be routinely included as part of the ‘total’ assessment for all cleft patients. Assessment may be performed to audit one surgeon, to compare different surgical techniques by one or multiple surgeons, or to make comparison among different centres. Timing of this assessment may be taken, as needed, at different stages along the cleft treatment pathway to answer a proposed clinical question.
One of the inherent uncontrollable factors affecting outcomes for cleft patients is the severity of the deformity. Although sharing many similarities, unilateral and bilateral clefts have unique outcomes and should be assessed independently. Similarly, the isolated cleft lip may be considered a distinct entity5 to the cleft lip and palate deformity. Despite this, however, external differences cannot be appreciated by a layperson in a social setting allowing both types to be assessed together with the same assessment tool.
The final aesthetic outcome for any cleft patient is the totality of treatments spanning a lifetime from birth to maturity along the cleft protocol pathway and may include some or all of the following: use of presurgical orthopaedics/nasoalveolar molding primary lip/nose repair, with or without postoperative nasal splinting, orthodontics, alveolar bone grafting, orthognathic surgery, cleft lip and/or nose revision. How each of these factors contributes to the final outcome remains to be clear. Nevertheless, it is important to remember that primary lip and nose repair is only one part of a patient’s overall aesthetic outcome. In future, acknowledging all the techniques used by one centre while assessing outcomes will allow for better comparison through multivariate analysis. Lastly, and most relevant to this study, is that comparing aesthetic outcomes is further complicated by centres using different aesthetic scoring methods, the majority of which have low intra- and inter-rater reliability.6–9
The most commonly used aesthetic measurement is the Asher-McDade index10 which uses a five-point scale to assess four facial features: nasal form, nasal symmetry, alignment of the vermilion border (frontal view) and nasolabial profile (lateral view). More recently, multiple new reference photographs were added to a modified Asher-McDade index; the result was named the Nasolabial yardstick after the Goslon yardstick.11 The Asher-McDade index has been used in many large, multicentre trials.12,13 The main problems reported with this scoring system are its’ cumbersome nature, lack of objectivity, need for expert opinion for better reliability and focus on the nose.8,13
Since the Asher-McDade index there have been numerous other scales of various reliability, however, a full literature review is beyond the scope of this article. Systematic reviews of published articles6–9 have found the majority of these scales use qualitative scoring systems of a subjective nature and reference photographs that are similar to the Asher-McDade index. In summary, there is a large number of rating scales requiring validation. Newer 3D and computer assisted technologies are emerging but are currently costly and not feasible. No doubt these techniques will be more important in the future.
Aim
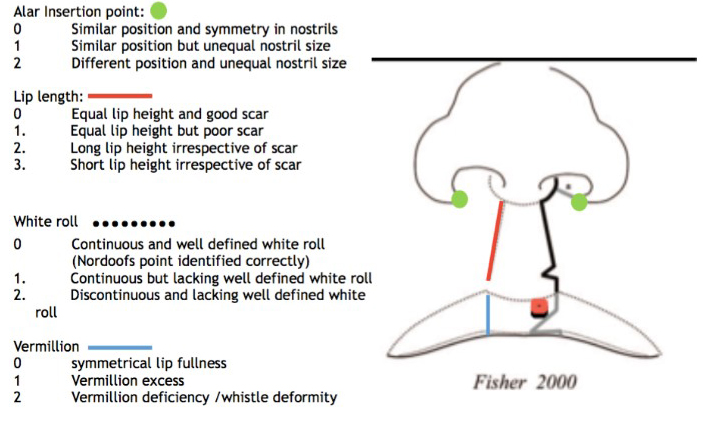
The authors sought to create a new tool for the assessment of the unilateral cleft named the Perth scoring system. The main aim was to ensure the assessment tool was easy to use for both surgeons and lay people, objective, reliable, effective in capturing a true assessment of a unilateral cleft lip and could be used at any stage along the cleft treatment protocol.
This scoring method is used to assess symmetry of four vital components of the cleft lip/nose repair (Figure 1), namely alar insertion point, lip length, white roll and vermillion. Each of the four components are scored using clear and objective descriptive criteria either from (0–3) or (0–2). The total score ranges from zero (best score) to nine (worst score). The purpose of this study was to validate the Perth scoring system as a reliable tool to assess the unilateral cleft lip/nose deformity.
_to_worst_(9).jpg)
Methods
Patients who underwent cleft lip revision by the senior author from 2008–2014 were identified using the hospital’s craniofacial clinical diary and hospital theatre database. Exclusion criteria included patients with bilateral cleft, prior revision surgeries, syndromes or inadequate photographs.
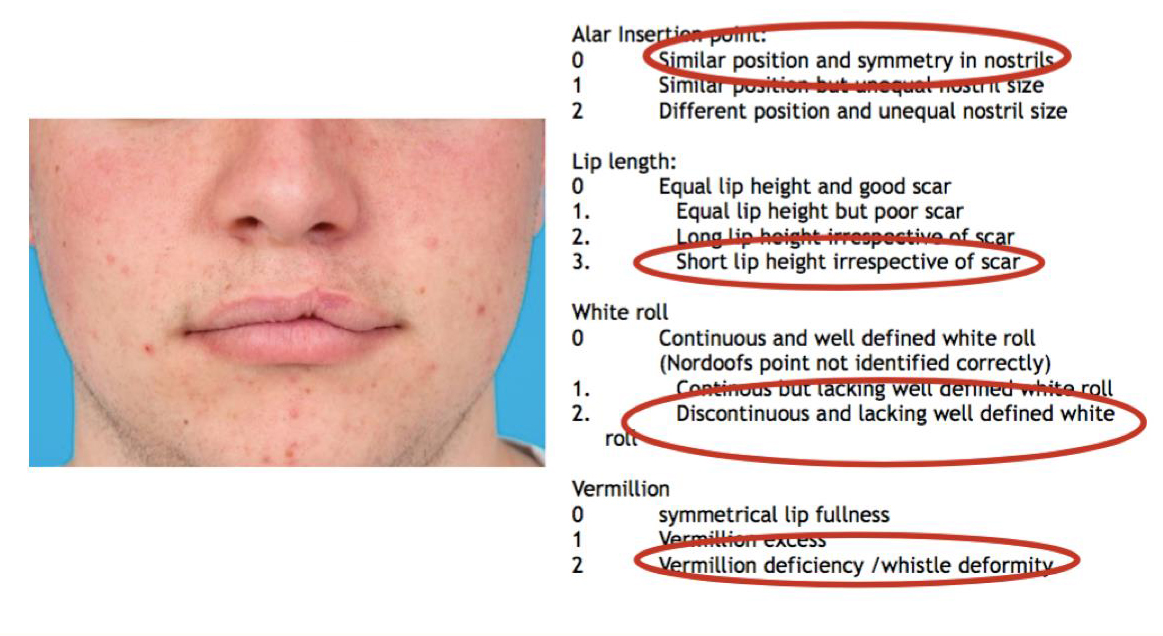
Pre- and postoperative revision photographs were collected and duplicates of each photo made. Photos were cropped to show the nose and lips only (figures 2–4). The shuffled photos were presented as projected slides at a conference. Raters were unaware that the photos included the same patients who had undergone surgical revision.
Prior to commencement, the scoring system was explained to the raters and three examples were shown (figures 2–4) with reasons as to why certain scores had been given for each case. Time was given to answer any questions regarding the scoring system. Slides were then presented in two sessions to reduce rater fatigue.
Scores were statistically analysed using Cohen’s kappa coefficient (IBM SPSS Statistics®, 1 New Orchard Road, Armonk, New York, 10504-1722, United States) to assess intra-rater and inter-rater reliability. Overall reliability of the scale was calculated using the intraclass correlation coefficient (ICC). Results were classified as poor (< 0.20), fair (0.21–0.40), moderate (0.41–0.60), good (0.61–0.80) or very good (0.81–1.00). Final analysis was also made to compare preoperative to postoperative scores to determine if there had been significant improvements in appearance following revision.



Results
Nineteen patients were identified through the hospital database who had undergone a cleft lip revision during the allocated time period and met the inclusion criteria. Each case had four photographs (duplicates of pre- and postoperative photographs) resulting in 76 slides.
Thirteen audience members completed the assessment and eleven of these had suitable results (there were two accidentally incomplete papers). Raters included four plastic surgery consultants, five plastic surgery trainees, one radiologist and one business representative.
Tables 1–4 show statistical results for intra-rater reliability for the four components of the scoring index (Figure 1); lip length, white roll, alar insertion point and vermillion. Cohen’s kappa results are shown for each rater. Intra-rater agreement scores from lowest to highest were: lip length (0.65), white roll (0.70), alar insertion point (0.78) and vermillion (0.78). Inter-rater reliability was extremely high for all four components of the scoring index (range 0.84–0.97, refer Table 5). Total ICC was 0.96 (p < 0.000)
In comparing pre- and postoperative scores, three cases were excluded as postoperative photos were taken too early and scars appeared immature. Almost all the resultant cases (15/16) showed significant improvement in scores post revision (Table 6). The mean sum of preoperative scores for all photographs was 46.97 (mean 3.13) compared to 31.07 (mean 2.07) post revision surgery (p < 0.007 paired t-test). The range of improvement was 1.09–5.59.
Discussion
Any new tool used in the analysis of an outcome must agree with the requirements of scientific reproducibility.
The Perth scoring system appears to be a valid and reliable tool to assess components of the unilateral cleft lip with results showing good/very good intra-rater and very good inter-rater reliability. The use of a single anterior 2D photograph was chosen as a more simple and practical option which better reflected the social scenario of daily life where patients have to interact ‘face-to-face’ with their peers. Furthermore, photographs are cropped to show only the nasolabial area by to reduce the influence of background facial attractiveness upon the assessment of cleft impairment.14,15
In contrast to previous methods, we used more objective criteria to establish the scores that are described using text alongside each rating. The categories chosen for assessment correspond to key areas in cleft lip and nose repair. In effect, the accuracy of repair and hence aesthetic outcome is translated into a scoring system. As a result, our scoring system is more useful in assessing the need for revision as it assesses—and places emphasis (with a higher score)—on key problems such as an asymmetrical alar base, short lip (highest score), discontinuous white roll and significant vermillion deficiency. Although some studies report 2D images as insufficient to assess scar quality, we believe it is still an important component and should be included in the scoring system.
Intra-rater agreement ranged from good to very good in our pilot study for each component (Table 7). Further field studies are required to test the reproducibility of this scoring method. It is well known that reproducibility is further improved by familiarity. Practice rater tasks are therefore highly recommended prior to commencing the scoring of subjects.6,16,17
Comparison of this tool to other published studies of cleft lip and palate (CLP) aesthetic indices are favourable. The most frequently used index developed by Asher-McDade reported fair to good inter-examiner rater agreement from their pilot study. The greater number of categories and reference photographs make the scoring system cumbersome and associated with poorer reproducibility. This index was subsequently utilised in the euro-cleft study with only the frontal and lateral photograph where lower inter-rater agreement was reported.18
Our review of published articles found one aesthetic index that was similar to our scoring system.19 The unilateral cleft lip surgical outcomes evaluation (UCLSOE) index scores symmetry of four individual components of the cleft repair (Cupid’s bow, lateral lip, nose and free vermillion). Each element is scored on a three point scale: excellent (2), (mild asymmetry (1), unsatisfactory (0). The four individual scores are then summed for a total score of lowest (0) to highest (8).
This index would be a useful tool to compare different surgical techniques as it assesses detailed parts of the lip repair, for example, comparison of both horizontal and vertical height of the lateral lip and assessment of the nose and lip also from a ‘worm’-eye view. Weaknesses of this index pertain to the need for two photographs in assessment as well as the use of subjective terminology such as ‘mild’ or ‘marked’ in the decision making. In addition, the index fails to distinguish more important problems from one another during the decision process. For example, in their assessment of the lateral lip both vertical and horizontal asymmetry are grouped together. This fails to recognise that a shorter vertical height is far more significant compared to a horizontal discrepancy which is usually not revised.
In contrast, our scoring system only allows a choice for a problem to be either absent or present by excluding use of subjective terminology such as ‘mild’, ‘moderate’, ‘severe’ and so on. This forces the rater to give the worst score for only significant discrepancies which translates to identification of obvious pathology. This makes it easy for different raters to choose a similar score which is shown by the very high intra- and inter-rater reliability. In addition, greater weighting has been given to stigmatising features such as short lip compared to a longer lip, significant deficiency of the vermillion (whistle deformity) or a discontinuous (step) white roll. A high score of nine would indicate failure in all key areas of the lip and nose repair necessitating a full cleft lip revision. The average scores for our own case series of patients who required revision was 3.13 with a mean improvement by one point post-revision (2.07).
Use of Figure 1 rather than reference photographs also makes it easier to visualise the areas for each component being assessed with colours to help with faster identification. This is less time consuming than looking at reference photographs, particularly for large case numbers needing assessment.
One question raised has been whether raters with different levels of expertise differ significantly with their scoring and outcomes. Our sample size of lay people was too small to show any significant discrepancies and this will need to be studied further with a larger test group. A systematic review by Zhu examined this question.20 Eleven articles were studied and the results were inconclusive with three studies reporting that laypeople were more critical than professionals, three studies reporting no significant difference between laypeople and professionals, and five studies reporting that professionals were more critical than laypeople when assessing facial appearance of patients with CLP.
Conclusion
The Perth scoring system appears to be a valid and useful tool for assessing unilateral cleft lip at any stage along the cleft treatment protocol. It was created to address problems found in previous rating systems which were too subjective and/or cumbersome. The high intra- and inter-rater reliability allow it to serve as a useful tool to compare surgical outcomes both within and between centres. Although designed primarily for cleft patients, it may be applied to all types of lip analysis (for example, after trauma). It will be necessary to conduct further field testing with a larger cohort to ensure the system’s surgical reproducibility among different centres and also for use by lay people.
Patient consent
Patients/guardians have given informed consent to the publication of images and/or data.
Conflict of interest
The authors have no conflicts of interest to disclose.
Funding
The authors received no financial support for the research, authorship and/or publication of this article.
Revised: July 16, 2019 AEST
Updated: June 23, 2021 AEST—new formatting